
Массивы - наиболее понятная и удобная структура данных для очень многих приложений. Они обеспечивают неизменное время доступа к их элементам, и эта структура применяется во многих практических алгоритмах. Большинство коммерческих библиотек на C++ имеет в своем составе контейнерный класс для реализации массивов переменной длины, и возможно миллионы программ на C++ используют массивы переменной длины как их основные структуры данных. Увеличение размера массива переменной длины обычно происходит при добавлении элементов в конец массив – стандартная операция для таких классов; если бы мы знали размер массива в начале, то, конечно же, нет причины использовать массив переменной длины.
Я хорошо знаю ограничения большинства реализаций массивов переменной длины, из исследования некоторого кода, который читает результаты запроса к базе данных. Не было никакого способа определить число строк, возвращаемых из запроса заранее, и код использовал коммерческий класс массива переменной длины, чтобы сохранить данные. Профилировщик сообщил мне, что класс массива делал невероятное число копирований элементов при изменении размеров. Это копирование занимало намного больше время, чем медленная передача данных из базы данных!
Вы могли бы сказать, что другая структура данных, типа связанного списка, лучше подойдет для этого приложения, но было бы слишком тяжело переделать весь старый код. Я решил пробовать сделать более эффективный класс массива, который имел тот же самый интерфейс как старый.
Много реализаций массивов переменной длины оставляют желать лучшего. Особенно, функция, которая добавляет новые элементы в конец массива, может вызывать проблемы с производительностью. Пример 1 показывает, возможно, самый плохой способ делать это. Имеются две основные причины, почему эта реализация настолько плоха.
· Чрезмерное копирование элементов. Если Вы добавляете 1000 элементов в массив, внутренний цикл копирует старые элементы в newTArray, при этом каждый раз массив расширяется, и общее количество операций копирования более чем 500,000. Этот, на первый взгляд, невинный код делает приблизительно более чем в 500 раз присвоений больше, чем необходимо для 1000 элементов, и дальше становит хуже, поскольку массив растет. Эта реализация - O(N2) (та же самая зависимость от времени как для пузырьковой сортировки) и очень неэффективная даже для маленьких массивов.
· Чрезмерное использование памяти. Во время операции копирования, и существующий массив и новый массив должны находиться в памяти в то же самое время, т.е. требуется двойная память для массива. Хуже того, каждый раз, когда массив растет, создается фрагмент памяти: старый массив. Этот фрагмент не может повторно использоваться, потому что новый массив будет больше, чем старый, как показано на рисунке 1. Это может увеличить требования к памяти почти в два раза.
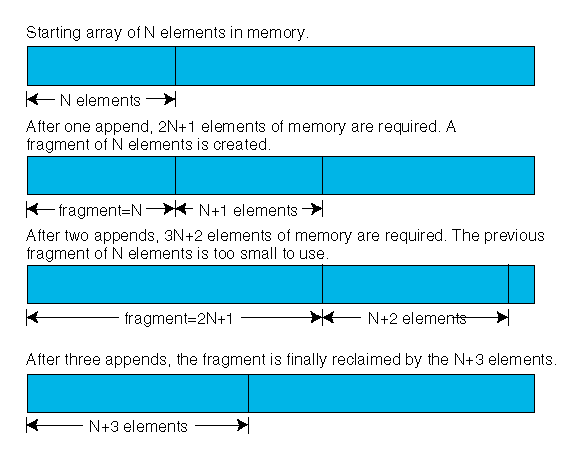
Рисунок 1. Использование памяти во время изменения размера массива.
void vArray::append( T &el )
{
// Очень плохая реализация
// массива переменной длины.
T *newTArray = new T [numElements+1];
for(size_t j = 0; j < numElements; j++)
newTArray[j] = tArray[j];
delete tArray;
tArray = newTArray;
tArray[maxElements++] = el;
}
Пример 1. Плохой способ изменения размера массива.
Интересно обратить внимание на то, что функция Си realloc() не имеет таких серьезных проблем. Причина в том, что, если массив является достаточным большим, то он будет распределен с конца кучи. Функция realloc может затем расширить буфер, увеличивая размер блока памяти, без необходимости копировать данные. К сожалению, это не работает в C++, потому что перераспределение не может вызывать конструкторы во вновь выделенной памяти. C++ требует, чтобы мы копировали элементы явно.
Можно попробовать решить эти проблемы, прибавляя к массиву более чем один элемент одновременно. Однако это не значительно уменьшает использование памяти. Даже при том, что это уменьшает общее число копирований, но все равно это будет это алгоритм O(N2), так как все, что вы сделали, так это улучшили производительность на константу. Например, если Вы добавляете 1000 элементов и наращиваете массив 10 элементами всякий раз, когда он заполнен, то при этом выполняется 10 + 20 + .. + от 1000 до 50,500 операций копирования, что является O(N2). Хотя при этом будет в 10 раз меньше копирований, чем прежде, но все еще в 50 раз больше копирований чем, необходимо.
Динамические массивы со временем добавления порядка O(1)
Чтобы преодолеть ограничения массивов переменной длины, я создал структуру данных, которая имеет быстрое постоянное время доступа подобно массиву, но избегает копирования элементов, когда она растет. Я назвал эту новую структуру "Дерево с хэш-массивами" (HAT - Hashed-Array Tree, по-английски, hat - шляпа), потому что в ней объединены некоторые возможности хэш-таблиц, массивов, и деревьев.
Хотя эта структура используется для реализации одномерных массивов, HAT на самом деле двумерны; смотри рисунок 2. HAT состоит из основного массива (Top) и нескольких листьев (Leaves), указатели на которые хранятся в основном массиве. Число указателей в основном массиве и число элементов в каждом листе одинаковое и всегда равно степени двух.

Рисунок 2. Структура данных HAT
Поскольку размер массивы Top и Leaf в степени 2, то можно быстро найти нужный элемент в HAT, используя поразрядные операции; смотри пример 2. Обычно, добавление элементов происходит очень быстро, так как последний лист может иметь пустое пространство. Менее часто нужно будет добавить новый лист, что также очень быстро и не требует никакого копирования.
inline size_t Hat::topIndex(const size_t j ) const
{
// Получить основной номер.
return j >> power;
}
inline size_t Hat::leafIndex(const size_t j ) const
{
// Получить вторичный номер
return j & ((1<<power)-1);
}
inline T &Hat::operator[](const size_t j) const
{
// Вернуть элемент HAT. Не проверки на выход за пределы массива.
return top[topIndex(j)][leafIndex(j)];
}
Пример 2. Быстрая индексация с побитными операциями.
Когда основной массив заполнен, становится немного более интересно. В моей реализации сначала вычисляет нужный размер (массивы Top и Leaf имеют тот же самый размер, оба в степени 2), затем копируются элементы в новую структуру HAT, освобождая старые листья и распределяя новые листья.
При этом подходе не происходит копирования большого количества элементов, как в предыдущей реализации динамического массива. Перекопирование происходит только, когда основной массив полон, а это только случается, когда число элементов превышает квадрат степени 2. Если N=4n, то общая сумма перекопирования 1+4+16+64+256+...+N. При использовании тождества (x(n+1)-1)=(x-1) (1+x+x2+x3+... + xn) Вы имеете 1+4+42+43+...+4n = (4(n+1) -1)/(4-1) = (4N-1)/3, или около 4/3 N. Это означает это, что среднее число дополнительных операций копирования - O(N) для последовательных добавлений N элементов, а не O(N2).
Методика перераспределения и копирования каждого листа по одному также значительно уменьшает непроизводительные затраты памяти. Вместо хранения полной копии HAT, необходимо иметь только память для дополнительного листа. Так как размер листа зависит от квадратного корня N, дополнительная память, которая требуется во время изменения размеров уменьшается с огромного, до процента от N. Например, если Вы добавили 1,000,000 элементов в HAT, дополнительная память, необходимая для изменения размеров, равна 1024 элементов или приблизительно 0.1 процент от памяти, уже используемой для данных массива.
Кроме того, фрагментация памяти уменьшается. Так как размеры Top и Leaf всегда увеличиваются к следующей степени 2, программа управления динамическим распределением памяти может объединить два освобожденных листа из меньшей HAT, чтобы распределить лист в большей.
Код реализации шаблона HAT включает в себя некоторую дальнейшую оптимизацию, чтобы устранить избыточное копирование, когда HAT увеличивается или уменьшается. Это достигнуто за счет увеличения фрагментации памяти, но приводит к улучшению производительности. В реализации массив Top увеличивается на множитель вышеупомянутого идеального размера, пока верхнее или нижнее пороговое значение не достигнуто.
Даже если изменение размеров - не проблема, эта реализация имеет и другие преимущества. Например, в 16-разрядной среде, никакой объект в куче не может превышать 64 КБ. HAT может управлять массивами намного большими, чем этот размер, если нет одиночных листьев больших, чем 64 КБ. Вы могли бы также расширять HAT, чтобы автоматически менять местами листья в памяти и на диске, чтобы поддерживать огромные массивы при минимуме памяти. В заключение, могут иметься преимущества для расширения HAT в три или большего количества уровней, чем в два уровня, которые использовал я.
Расход памяти
Я уже предположил, что HAT использует намного меньше памяти, чем стандартный подход к перераспределению и копированию всего массива. Чтобы увидеть насколько меньше, я буду вычислять затраты памяти для HAT при изменении размеров.
Самый плохой случай - это когда элементы в HAT имеют тот же самый размер, как и указатели, а число элементов на один больше, чем значение для изменения размеров. Если элементы того же самого размера, как и указатели, Вы можете добавлять неиспользуемую часть основного массива в любой незадействованной памяти в листьях, таким образом, доводя до максимума количество незадействованной памяти как процент от данных в массиве; смотри таблицу 1. Вы можете видеть, что, поскольку HAT растет, процент от незадействованной памяти в самых плохих случаях сильно уменьшается. Вообще, трата памяти в самом плохом случае - (top+leaf-1) ~= 2*sqrt(N) = O(sqrt(N)). Если Вы ожидаете, что последний лист будет половиной полного, ожидаемая трата памяти уменьшается на (top + leaf/2) ~= 1.5*sqrt(N), что все еще O (sqrt (N)). Эти непроизводительные издержки можно сравнить другими структурами данных, которые могут добавлять элементы за время O(1). Например, однонаправленный список требуют O(N) непроизводительных издержек памяти (один указатель для каждого элемента).
Таблица 1. Наихудший случай потери памяти
|
Размер Top/Leaf |
Наихудшее N |
Наихудшие затраты (top+leaf-1) |
Процент данных |
|
2 |
3 |
1+2=3 |
100 |
|
4 |
5 |
4+3=7 |
140 |
|
8 |
17 |
8+7=15 |
80 |
|
16 |
65 |
16+15=31 |
48 |
|
32 |
257 |
32+31=63 |
25 |
|
64 |
1025 |
64+63=127 |
8 |
|
128 |
4097 |
128+127=255 |
6 |
|
256 |
16385 |
256+255=511 |
3 |
Эффективность
Во встроенном массиве C++, адрес элемента вычисляется добавлением индекса элемента, умноженного на размер, к началу массива. Для сравнения, поиск адреса элемента в HAT требует адресации в двух таких массивов, указатель разыменовывает, и вычисляются topIndex и leafIndex. При помощи предвычисления (1<<power)-1, это позволяет адресовать два массива, разыменовать указатель, битовый сдвиг, и операцию &. На современных процессорах, последние три операции могут быть выполнены очень быстро. Это означает, что элементы HAT, могут быть разыменованы за два раза большее время, чем массив C++.
Рисунок 3 показывает результаты реализации быстрой сортировки, сравнивающей стандартные массивы C++ и HAT. Этот алгоритм использует ссылки массива очень интенсивно, и поддерживает оценку, что HAT – в два раза медленнее, чем обычные массивы.

Рисунок 3. Быстрая сортировка со стандартными массивами и HAT.
На рисунке 4 сравниваются два типа массивов в слегка различном окружении. В этом случае N случайных чисел добавляются в массив и затем сортируются. Хотя HAT медленнее при работе со ссылками, но добавление происходит быстрее, и соответственно быстрее полное выполнение этого теста.

Рисунок 4. Добавление и сортировка со стандартными массивами и HAT.
Тесты сравнивают HAT с классом с массива переменной длины, выполненным стандартным способом (перераспределение и копирование), который растет на 64 элемента всякий раз, когда происходит изменение размера. При этом использовался алгоритм быстрой сортировки на шаблоне, который принимает любой класс с массивом переменной длины. Все эталонные тесты были выполнены на рабочей станции 100Mhz HEWLETT-PACKARD 700 из серии PA-RISC, под управлением HPUX 9.01 с 256 МБ памяти.
Заключение
HAT - практический и эффективный способ реализовать массивы переменной длины. Они предлагают хорошую производительность порядка O(N), чтобы добавить N элементов к пустому массиву и требуют всего лишь O (sqrt (N)) непроизводительных затрат памяти. Они обеспечивают все и стандартные возможности нормальных массивов, включая произвольный доступ к элементам. Они имеют хорошую производительность и характеристики использования памяти при любом числе элементов, и не требуют никакой специальной настройки приложения.
Хотя HAT требуют большего времени при обращении к их элементам, этот недостаток, часто далеко перевешивается быстрым изменением их размеров, эффективным использованием памяти, и высоким удобством для программиста. Они предлагают сильные преимущества над другими методами реализации массивов переменной длины.
Ссылки:
Cline, M.P. and G.A. Lomow, C++ FAQs, Reading, MA: Addison-Wesley, 1995.
Cormen, T.H., C.E. Leiserson, and R.L. Rivest. Introduction to Algorithms, Cambridge, MA: MIT Press, 1990.
© Эдвард Ситарски – вице президент Numetrix Ltd.
Его электронный адрес: ed@tor.numetrix.com.